

Wesam AlGhazawi
Observability for DevOps: Why It’s More Than Just Monitoring
The DevOps Challenge
In modern software delivery, speed is everything. New features roll out quickly, updates happen often, and user expectations are higher than ever. For DevOps teams, this means one thing: keeping systems healthy while racing against time.
The challenge? Systems today are built from countless moving parts like microservices, APIs, cloud resources, and integrations.
All working together in real time. When something breaks, the ripple effect can be instant and widespread. Every second counts, and guessing the cause is not an option.
That’s where Full Stack Observability steps in.
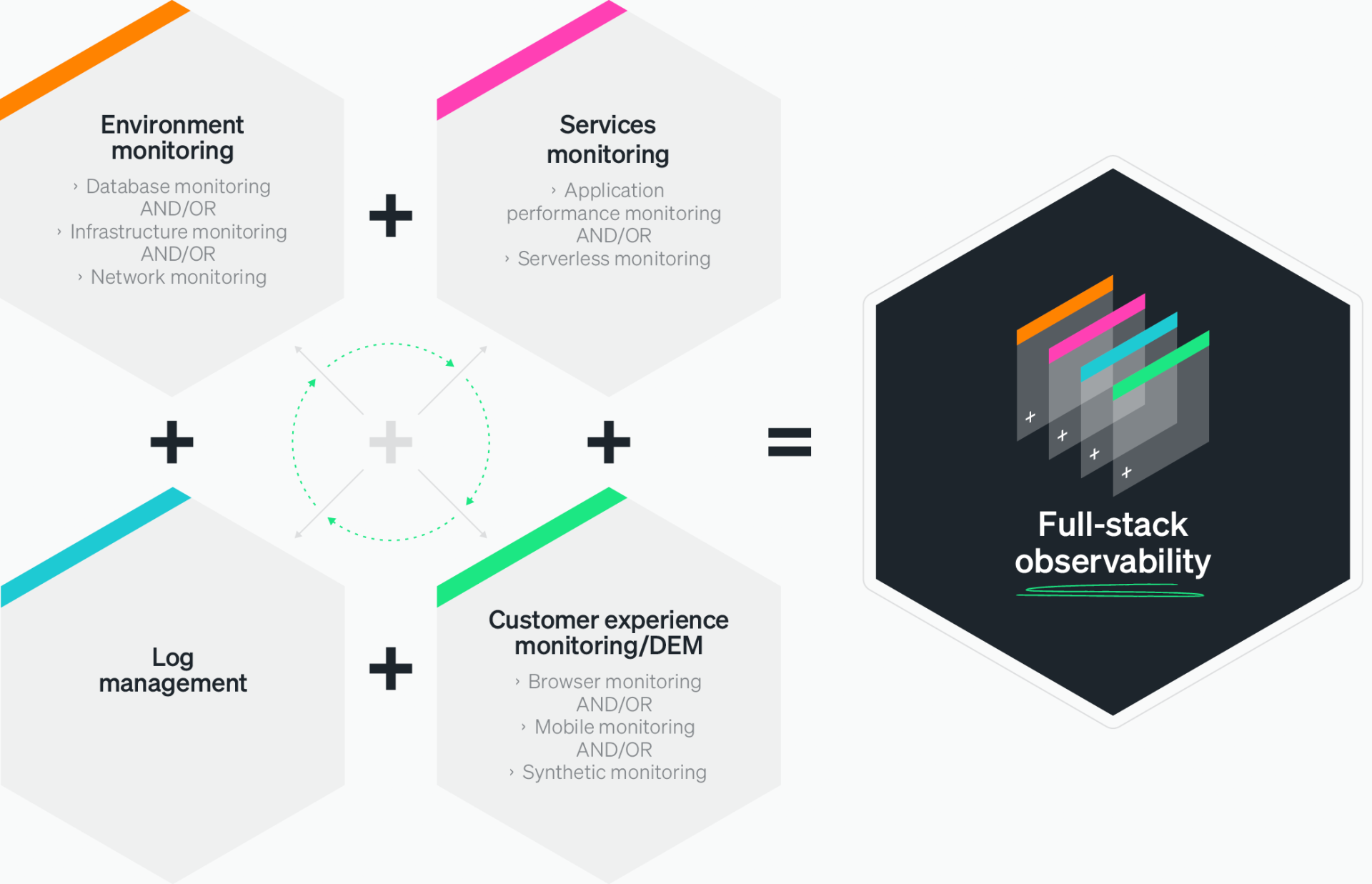
What Is Full Stack Observability?
Traditional monitoring can tell you something is wrong when there's a CPU spike, a server down, or a slow response time. But it stops there. You still have to dig, investigate, and connect the dots.
Full Stack Observability changes the game. It gives teams a complete, connected view across the entire system, from the underlying infrastructure to services, APIs, and even the end-user experience. It doesn’t just report the problem; it helps explain what happened, why it happened, and how to fix it fast.
Full Stack Observability collects and connects four key types of data:
1. Logs: Are detailed event records for tracking activity.
2. Metrics: Performance numbers that show the system’s health over time.
3. Traces : The step-by-step path an action takes through different services.
4. Real user data: How the application performs for actual users.
By combining all these, observability creates a real-time, high-definition picture of the system.
Example: A monitoring tool might simply say “Server is down.”
where Observability says, “The server crashed because a database query from the last deployment caused a memory overload.”
Why DevOps Teams Need Observability Tools
- Noise Reduction
In complex systems, one issue can trigger dozens of alerts. Without filtering, teams waste hours chasing the wrong leads. Observability tools group related alerts together and highlight the ones that matter most. This removes the clutter and makes sure teams focus on problems that have a real impact.
- Root Cause Analysis
When an outage hits, speed is everything. Observability gives teams a clear path to follow from the symptom to the source. Whether it’s faulty code, a misconfiguration, or an external service failure, finding the real cause becomes faster and more accurate.
- Team Collaboration
Incidents often involve multiple teams; developers, operations, SREs, and sometimes even vendors. Observability gives
everyone a shared, live view of the system, so they can work together without delays, confusion, or duplicated effort.
The Impact on DevOps
- Faster fixes → Reduce downtime and restore service quickly.
- Proactive prevention → Spot early warning signs before they turn into incidents.
- Better user experience → Monitor real-world performance and make smarter changes.
- Stronger teamwork → Everyone works from the same facts, in real time.
What DevOps Teams Really Want from Observability
DevOps teams need clarity, context, and confidence. They work in environments filled with fragmented logs, overwhelming alert storms, and blind spots in cloud-native systems. When issues strike, they need answers quickly not just more data to sift through.
Here’s what matters most to them, and how observability delivers:
- Context, Not Chaos
A spike in latency or a service outage means little without the full story. Observability connects metrics, logs, and traces to reveal the ripple effect across the system turning isolated alerts into meaningful insight.
- Fast Root Cause Analysis
Distributed systems are complex. Observability allows teams to trace requests across multiple services and pinpoint the exact source of failure in seconds, not hours.
- Noise Reduction
When every alert demands attention, nothing gets priority. Observability platforms filter and correlate events, surfacing only the issues with real business impact.
- Shared Visibility
Dev, Ops, and Security teams often work with separate tools and views. Observability creates one shared window into the system so everyone works from the same facts and moves in sync.
- A Predictive Edge
The best observability tool predicts. It highlights anomalies, regression trends, or drift before they turn into outages, helping teams protect service levels.
Bringing It All Together with Acuative
For modern DevOps teams, Full Stack Observability is not a nice to have tool, it’s a neccassity. It’s the key to moving from reactive firefighting to proactive stability.
At Acuative, our Full Stack Observability solution unifies logs, metrics, traces, and user data into one intelligent platform. We help teams reduce noise, get to the root cause faster, and work together more effectively. Whether it’s monitoring infrastructure, applications, APIs, or the end-user experience, our solution delivers the clarity and speed DevOps teams need.
About Wesam

Wesam Alghzawi is one of our skilled Cloud & DevOps Engineers specializes in building and managing secure, scalable, and high-performing cloud environments. As a certified observability engineer, he leverages advanced monitoring, logging, and analytics capabilities to provide complete visibility into systems and applications. His expertise ensures proactive issue detection, faster incident resolution, and optimized system performance.