
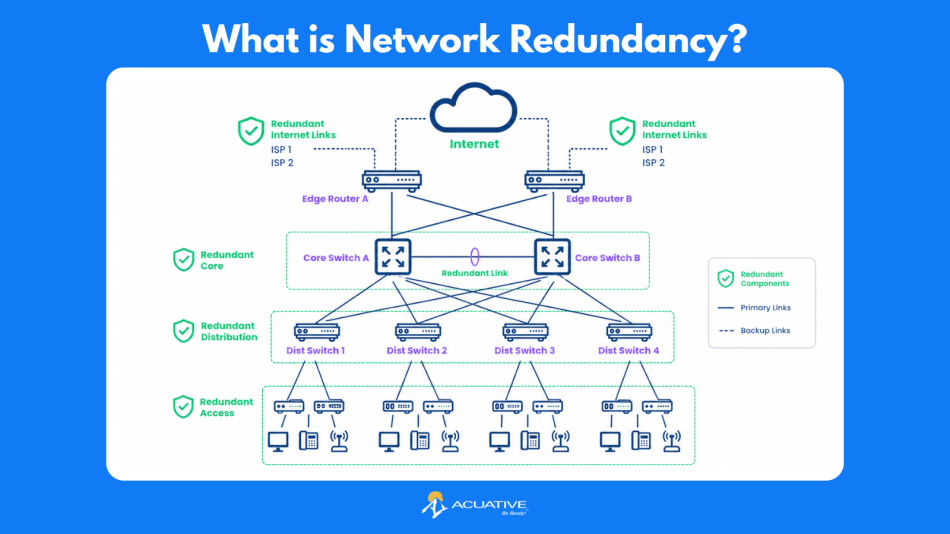
Network redundancy is the practice of incorporating duplicate or backup network components like links, devices, power supplies, or entire routing paths. This way, if any single element fails, traffic automatically reroutes through an alternative without disrupting operations. The core goal is to eliminate single points of failure: any component whose loss would take down connectivity for users, applications, or entire sites.
In computer networking, redundancy operates across multiple layers simultaneously. At the physical layer it may mean dual uplinks or geographically diverse fiber routes. At the network layer, dynamic routing protocols recalculate paths in milliseconds. At the application layer, load balancers and failover clusters absorb the work of a failed node. A mature redundancy strategy addresses each of these layers in combination rather than in isolation.
Network redundancy isn't a luxury reserved for large enterprises. Any organization whose operations depend on connectivity needs a deliberate redundancy strategy before an outage forces the conversation.
— Acuative Network Architecture Team
The ultimate expression of redundancy is high availability (HA), typically measured in "nines of uptime." Five nines, or 99.999%, translates to fewer than 5.26 minutes of downtime per year. Achieving that standard requires intentional, multi-layered design backed by regular testing. It does not happen by accident.

Why Network Redundancy Matters
Modern organizations run on connectivity. A failed core switch, a severed fiber path, or a carrier outage can halt e-commerce transactions, freeze cloud workloads, strand remote workers, and expose the business to regulatory penalties within minutes. The business case for redundancy is straightforward: building it in costs far less than living without it.
ITIC has estimated the average cost of IT downtime at roughly $300,000 per hour for mid to large sized enterprises. For organizations in financial services, healthcare, or retail, that figure climbs considerably higher once lost revenue, SLA penalties, and reputational damage are factored in. Network redundancy directly compresses that risk by ensuring that no single hardware, software, or carrier failure can take the business offline.
The question isn't whether your network will experience a failure. There will be failures, but have you built a network that can survive them without anyone noticing?
Beyond the financial case, redundancy is frequently a compliance requirement. Regulations like HIPAA in healthcare and PCI DSS in payments mandate demonstrable availability and disaster recovery capabilities. A redundant network architecture is often a prerequisite for passing audits, not merely a best practice recommendation.
How Network Redundancy Works
Redundancy works by ensuring that every critical network function has at least one backup capable of taking over immediately. There are two fundamental operating models that define how primary and backup components relate to one another.
In an active-active configuration, multiple components operate simultaneously and share the traffic load. If one fails, the remaining components absorb its traffic without any switchover delay. This model maximizes both throughput and availability, though it requires more hardware and more complex configuration to implement correctly.
In an active-passive (or hot standby) configuration, a primary component handles all traffic while a standby monitors passively and activates only on failure. This model is simpler and less expensive, but introduces a brief switchover delay (typically measured in seconds) while the standby takes over.
When a failure is detected by a routing protocol, a heartbeat signal, or a monitoring system, traffic is redirected to the backup path. This process, called failover, can occur in under a second with modern protocols like BFD. Once the primary is restored, traffic may fail back automatically or be returned manually depending on organizational policy.
Types of Network Redundancy
Redundancy can and should be implemented at every layer of the network stack. The table below summarizes the most common categories, what they protect against, and how they're typically deployed.
| Type | What It Protects Against | Common Implementation |
|---|---|---|
| Link Redundancy | Failure of a single physical or logical connection between devices | Dual uplinks, link aggregation (LACP / 802.3ad) |
| Device Redundancy | Failure of a router, switch, or firewall | Stacked or clustered devices with HSRP or VRRP virtual gateway |
| ISP / WAN Redundancy | Carrier outage or circuit failure cutting internet access | Dual-carrier WAN, SD-WAN with automatic path selection, BGP multi-homing |
| Path / Route Redundancy | Loss of a routing path through the network core | OSPF, IS-IS, or BGP with multiple advertised routes |
| Power Redundancy | Power failure at the device or facility level | Dual power supplies, UPS, backup generators |
| Geographic Redundancy | Site-level disaster, e.g. flood, fire, or large-scale power event | Multi-data-center or multi-cloud architecture with DNS-based or anycast failover |
Key Protocols That Enable Network Redundancy
Several industry-standard protocols underpin redundant network design. Understanding which protocol operates at which layer and how quickly it responds to a failure is essential when evaluating or designing a redundancy architecture.
| Protocol | Layer | Purpose | Failover Speed |
|---|---|---|---|
| HSRP / VRRP | Layer 3 | First-hop router redundancy via a shared virtual gateway IP | Seconds |
| STP / RSTP | Layer 2 | Prevents switching loops; activates blocked backup links on failure | STP: up to 30s · RSTP: ~1s |
| OSPF / IS-IS | Layer 3 | Interior gateway routing with fast convergence across multiple paths | Sub-second (with BFD) |
| BGP | Layer 3 | Multi-homed ISP connectivity and inter-domain routing | Seconds to minutes |
| LACP / 802.3ad | Layer 2 | Link aggregation for simultaneous redundancy and increased throughput | Immediate (active-active) |
| BFD | Multi-layer | Rapid failure detection that accelerates convergence in routing protocols | Milliseconds |
Network Redundancy Best Practices
Adding extra hardware is only part of the equation. A redundant network that hasn't been designed carefully, configured correctly, and tested regularly can fail to protect you when you need it most. The following best practices separate genuine resilience from the mere appearance of it.
Identify every single point of failure before you design: Conduct a thorough topology audit before spending anything on redundant hardware. Document every device, link, power circuit, and upstream provider. Any component without a backup is a risk. Prioritization decisions only make sense once you have a complete picture of your exposure.
Use diverse physical paths, not just diverse devices: Two cables in the same conduit, or two circuits from the same carrier entering the building at the same point, share a failure domain. True redundancy requires separate conduits, separate carrier entry points, and ideally separate geographic paths to create physical diversity. This is especially critical for WAN and last-mile circuits, where a single trench cut can eliminate both primary and backup simultaneously.
Connect to more than one ISP: A single internet service provider is one of the most common single points of failure for branch offices and headquarters alike. Multi-homed WAN connectivity across different carriers with different physical entry points ensures that a carrier outage doesn't isolate your site. SD-WAN makes this practical and cost-effective even for smaller locations, automatically steering traffic across MPLS, broadband, LTE, or 5G connections based on real-time health checks.
Automate failover: Manual failover is too slow and too prone to error for modern network operations. Routing protocols, SD-WAN policies, and load balancers should all be configured for automatic health-check-based failover so that traffic reroutes the moment a failure is detected instead of someone having to notice the outage and decide to act.
Test your redundancy: A failover mechanism you've never tested is a failover mechanism you don't actually have. Schedule regular "game day" exercises where you deliberately fail components and verify that recovery meets your Recovery Time Objective. Misconfigurations discovered in a controlled test cost far less than those revealed during a real outage.
Monitor actively and alert swiftly: When a redundant path activates, it means your primary just failed and you're now operating without a safety net. Continuous monitoring must alert your operations team immediately so the failed component can be diagnosed and restored before a second failure eliminates the backup as well. Redundancy buys you time; monitoring ensures you use that time wisely.
Network Redundancy vs. Network Resilience
These terms are frequently used interchangeably, but they describe related yet distinct concepts. Network redundancy is a design attribute that denotes the presence of duplicate components and alternate paths built into the infrastructure. Network resilience is a broader operational outcome: the ability to detect a problem, adapt to it, recover from it, and learn from it.
The distinction matters in practice. An organization can invest significantly in redundant hardware and still lack resilience if failover has never been tested, monitoring isn't configured correctly, or the operations team lacks documented runbooks for recovery scenarios. Redundancy is a necessary condition for resilience, but it is NOT sufficient on its own.
Think of network redundancy as the infrastructure you build, and network resilience as the outcome you achieve. The gap between the two is where most organizations discover their real exposure to outages.
— Acuative Network Architecture Team
Frequently Asked Questions About Network Redundancy
What is network redundancy in computer networking?
Network redundancy is the practice of adding duplicate network components, e.g. links, devices, or paths, so that if one element fails, traffic automatically reroutes through an alternative, keeping the network operational without interruption. The core goal is to eliminate any single point of failure that could bring down connectivity for users or applications.
Why is network redundancy important for businesses?
Downtime is expensive. Gartner estimates the average cost at $5,600 per minute, and for industries like financial services or healthcare, the figure is often much higher once lost revenue, SLA penalties, and reputational damage are factored in. Beyond cost, redundancy ensures business continuity, supports regulatory compliance, and preserves customer trust in a way that recovery after an outage cannot fully restore.
What is the difference between network redundancy and network resilience?
Network redundancy refers to having duplicate components ready to take over if a primary fails. Network resilience is a broader concept that encompasses redundancy plus the organizational processes, monitoring capabilities, testing discipline, and operational expertise needed to detect, adapt to, and recover from any disruption. Redundancy is the infrastructure; resilience is the outcome.
What protocols are used to implement network redundancy?
The most common protocols include HSRP and VRRP for first-hop router redundancy, RSTP for fast Layer 2 link recovery, OSPF and BGP for dynamic routing with automatic path recalculation, LACP for link aggregation, and BFD for millisecond-level failure detection. The right combination depends on which layers of the network are being protected and the failover speed required.
What is the difference between active-active and active-passive redundancy?
In active-active redundancy, multiple components run simultaneously and share the traffic load, providing both redundancy and higher aggregate throughput with near-instant failover. In active-passive redundancy, a primary handles all traffic while a standby monitors and only activates on failure. Active-passive is simpler and less costly, but introduces a brief switchover delay during failover events.
How do I know if my network has adequate redundancy?
Start by mapping every component in your topology and identifying those with no backup to find your single points of failure. Then evaluate your Recovery Time Objective (RTO): how long can the business tolerate an outage? If your redundant paths have never been tested end-to-end in a controlled failover exercise, they may not perform as expected during a real failure. A professional network assessment is the fastest way to surface gaps and prioritize what to fix first.
Is SD-WAN a form of network redundancy?
Yes. SD-WAN is one of the most effective enablers of WAN-level redundancy available today. It bonds multiple underlay connections, including MPLS, broadband, LTE, 5G, and automatically steers traffic across the healthiest path in real time based on continuous performance monitoring. This gives branch offices and remote sites genuine WAN redundancy without the cost of traditional dual-MPLS configurations.
Ready to Build a Redundant, Always-On Network?
Understanding network redundancy is the first step, but designing, deploying, and managing a truly resilient network requires deep expertise, proven methodology, and the right technology partnerships. That's where Acuative comes in. Our Managed Network Services include end-to-end redundancy architecture, multi-carrier WAN design, SD-WAN deployment, and 24×7 NOC monitoring so your team can focus on the business while we ensure the network never lets you down. Whether you're building from the ground up or hardening an existing environment, our Professional Services team can assess your current topology, identify every single point of failure, and deliver a prioritized redundancy roadmap tailored to your industry, compliance requirements, and budget. Contact Acuative today to schedule a complimentary network resilience review.